
Pivot Tables Without the Pivot “Table” (Part-II)

If you haven’t read Part-I then I will come and haunt you in your dreams.
.
.
.
Now that we have our XML ready, we can mimic pivot table behavior with it.
Well, Kinda.
Pivot tables are easy to customize, whereas what I’m about to show you right now is not nearly as customizable and only pretends to output Pivot Table data.
If you want the automation to produce different layouts i.e., provide inputs and expect the bot to dynamically synthesis data based on that, then you are in for a major challenge.
You could maybe get a little fancy with it and implement conditional branches of logic, but the complexity will skyrocket giving both you and your support team a massive headache to deal with.
If your usecase is static i.e., you always want to find the percentage/sum/average of grouped columns, then you may apply this.
Couldn’t You Think of a Better Usecase?
Nope.
Lets begin!
XPath Functions, and Why No One Cares About Them
There is very little information on the world wide web regarding XPath Functions.
I’ve looked everywhere.
There aren’t any comprehensive guides on how to work with them…or at least any guide that I could work with.

what were we talking about again?
So I had to browse through StackOverflow to understand how it works, and how I can make them work for me.
I came across some interesting functions over at StackOverflow, but they couldn’t be used with XML 1.0.
They were reserved for XML 2.0 and I didn’t want to explore that just yet.
I’ll explore XML 2.0 another day so lets dive into today’s exercise!
The Code So Far…
If you remember, we logged XML to a text file in our previous article. We won’t be doing that here, since the XML Actions can initialize not only files, but variables as well.
Since we appended XML data to a string, we can directly initialize it like so:

I think now would be a good time to discuss what we are trying to achieve.
In the given dataset, we have six products.
Our goal is to find the profit generated by each product, and also their percentages to the total profit.
If all six products brought in 100$, then the total is 600$, with each product contributing 20%.
It’s a rather straightforward outcome, but one that involves more operations if we were to compute them using Excel Actions.
Sure, the Set Formula Action can get things done in a jiffy, but it gets complicated when performing computations with grouped data.
Now That That’s Established
Now we retrieve the entire collection of nodes and start iterating through them product by product…but there is a catch.
If you have a dataset that looks like this:
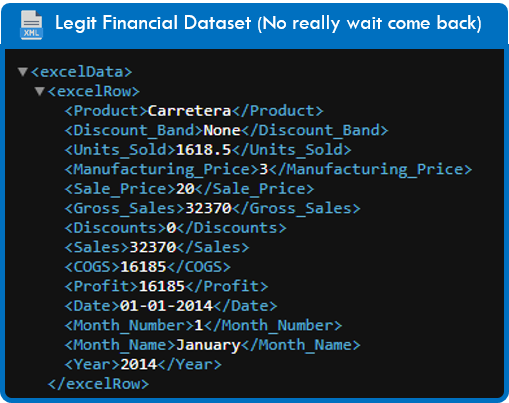
Then you can’t simply iterate through each node. I mean you can, but that wouldn’t make any sense.
Now I’m not making any sense.
Yes, You’re Not Making Any Sense.
Okay, Okay.
Let me put it this way, we have six products right?
We have to compute values based on each product right?
Assuming that the above statements are true, we may conclude that it isn’t necessary for us to iterate across each item, but group the items and perform operations on the grouped collection.
Starting to make sense now?

If all of that went over your head, then maybe the solution might shine some much needed light on the topic that I obscured with pointless explanations.
But First, The XPath.
If you build an incredibly basic XPath, it will detect multiple matches.
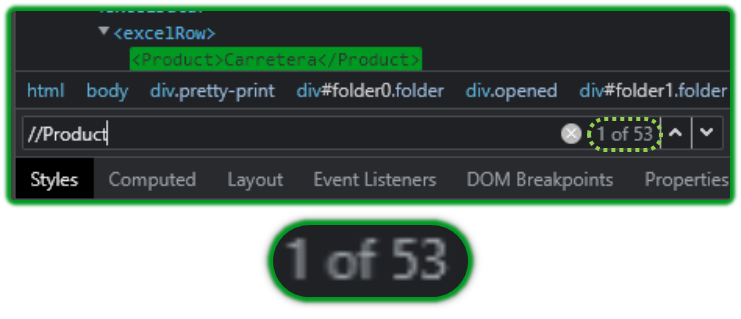
But what if I wanted to detect only unique Product Items? Is that even possible?
I wouldn’t be writing this if it weren’t, now would I?
//Product[not(text() = preceding::Product/text())]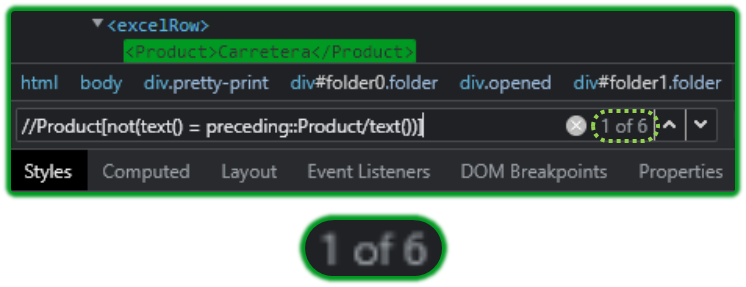
This XPath has been blessed with some intelligence which is nothing more than a clever play on conditional statements.
This also accounts for most of the AI/ML infused RPA “usecases” our sales representatives like to dangle in front of customers.

The XPath looks for those Products which are not equal to the one before it i.e., it will always return unique matches for the same node.
This isn’t something I can explain in detail, because if I did you would run away. Spend sometime with it, and she will reveal her secrets to you.
Now that we have the required collection of nodes we can start using XPath Functions.
Computing Profits
XPath functions aren’t very different from XPaths. The Function consumes whatever the XPath retrieves and delivers an output.
If you are good with creating XPaths, then using XPath Functions will be a cakewalk.
I think that’s enough SEO for XPaths (Hehehe).
Since we are iterating through each node, we won’t hardcode the products. The Loop will take care of that, which is convenient as it will adjust itself accordingly – regardless of whether we add or subtract products.
So lets look at the XPath before feeding it into a function.
//Product[text()='$str_currentNode$']/following-sibling::Profit/text()This XPath might seem similar to the one we explored earlier, but its not.
It searches for the product, then navigates to the sibling node which contains the profit value we are interested in.
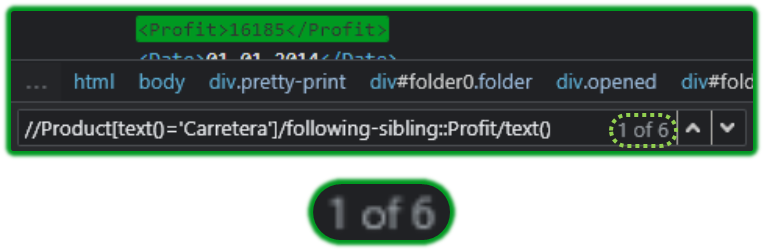
//Product[text()='Carretera'] -> Navigates to Product nodes containing ‘Carretera’
following-sibling -> Searches for its sibling i.e., doesn’t ascend or descend.
::Profit/text() -> Searches for a node(Profit) and retrieves its text.The XPath Function that will compute the sum is given below:
sum(//Product[text()='$str_currentNode$']/following-sibling::Profit/text())Pretty simple, right?
Computing Percentages
Let’s make things a little more tricky.
This time we will compute the percentage profit each product contributes to the whole. To do this, we have to divide the profit per product by the total profit.
We already know how to compute the profit per product, so part one is taken care of.
sum(//Product[text()='$str_currentNode$']/following-sibling::Profit/text())Next, we have to divide it by the total profit.
This is pretty straightforward as well, since we have to detect every instance of Profit in the xml.
sum(//Profit)Now to bring everything together:
substring((sum(//Product[text()='$str_currentNode$']/following-sibling::Profit/text()) div sum(//Profit))*100,0,5)The div is used to divide the amount which is then multiplied by 100 to acquire the percentage.
The substring is an additional step I put in place to improve the aesthetics of the result.
There is a round function, but it doesn’t offer any option to round the decimal values to the last n digits i.e., it gets rid of the decimal part entirely.

And with that, you have a pivot table-ish automation that you can serve to your customers!

In Conclusion
If you have worked with XPaths, then working with XPath Functions isn’t going to be too much of a leap.
Sure, we mostly use the XML Action Package only to read configuration files, but you could get a little creative with it and perform operations similar to the one I just showed you.
Who knows, it might come in handy one day.