
Advanced Xpath Concepts to Boil Your Brain
What are Xpaths you ask?
Think of them as tiny connectors which enable us to interact with elements present inside Web Applications.
Why cover Advanced Concepts in Xpaths Before covering Basics you ask?
Xpaths are super easy to learn.
You can learn them in less than a day if you understand HTML…but to answer your question, this didn’t cross my mind until I started uploading this article to WordPress.
So let me draw your attention away by showing you an example of an easy Xpaths:
//h3[@class='LC20lb MBeuO DKV0Md']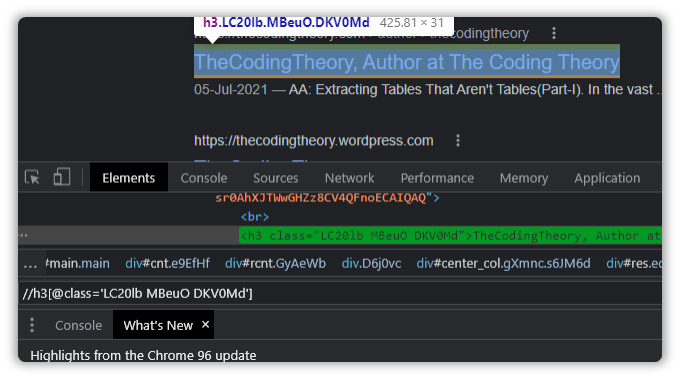
But stuff like that is just childsplay.
Here is an example of a slightly more advanced Xpath:
(//h2[@class='product-cards_product-card__title__2qoXd'])[1]/following-sibling::div/child::div/following-sibling::span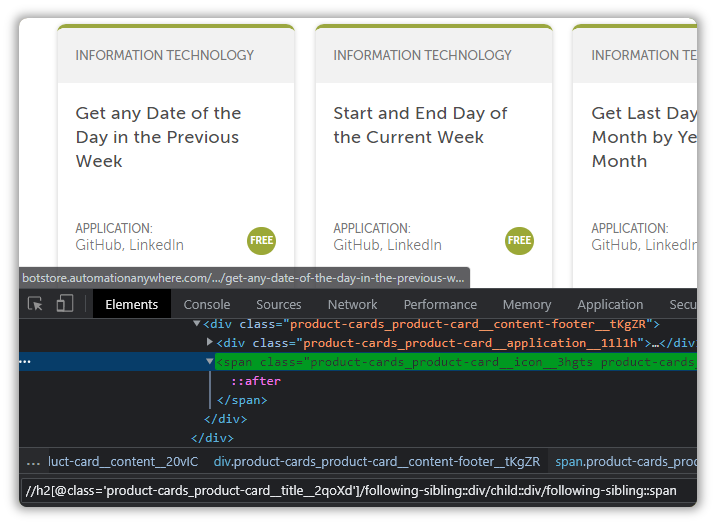
With Advanced Xpaths, we can navigate across nodes and detect elements that our Capture Action is sometimes unable to detect.
These Xpaths might seem a little scary at first, but tha– hey wait come back!

There are two packages for web automation in Automation Anywhere:
- Universal Recorder
- Capture
- Web Automation Package
If you want to get really creative with it, you could also say that JavaScript, Python and VBScript can also be used to automate websites, but it isn’t tailored for web automation.
Didn’t You Say Two? I can See Three!
My math is pretty wicked, but there are still only two ways to automate websites properly.
Both, the Universal Recorder and Capture translate your interactions into Recorder: Capture Actions, so they are from the same family.
I would recommend using the Recorder: Capture Action, since it allows for better flexibility over your automations. You can read more on the Capture Action here.
Then comes the Web Automation Package, which deserves an article of its own, we won’t explore any of that today.
The Capture Action alone helps us build robust web automations, as long as you know how to create Xpaths, which is why it’s an important topic.
The Xpath Less Taken
Hopefully, the cringe from reading that title must have subsided by now.
Onto the topic at hand, if you have worked with selenium, or understand HTML, which by the way is the bare minimum prerequisite for reading any of this, then I can guarantee that you won’t face any difficulty learning them.
It’s just HTML manipulation, nothing too complicated, and learning Xpaths helps us craft complex trajectories for our automations to follow.
You can get really creative with them as well.
Clubbing them with counter variables and plugging them into loops that will iterate as long as a condition is satisfied, is one such way of “getting creative with them”.
The example stated above is what we use to scrape data of websites.
If you are just starting out, I would recommend checking this out before you proceed.
Exercise Time!
We will explore the DOM structure for the item shown in the screenshot below:
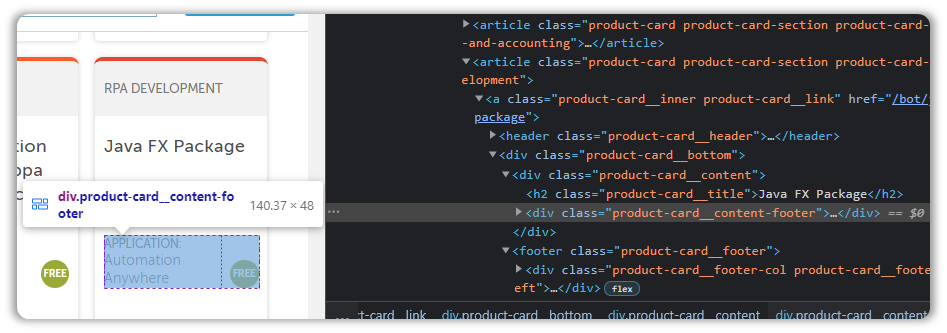
The JavaFX Package is something I wish I’d known about sooner.
You can view variable properties as you run the process, without having to toggle it over to Debug, which is pretty neat.
I would recommend checking it out AFTER reading this article.

Lets study its properties.
To do so, simply right-click and press inspect.
Now lets see in how many ways we can dissect this specimen.
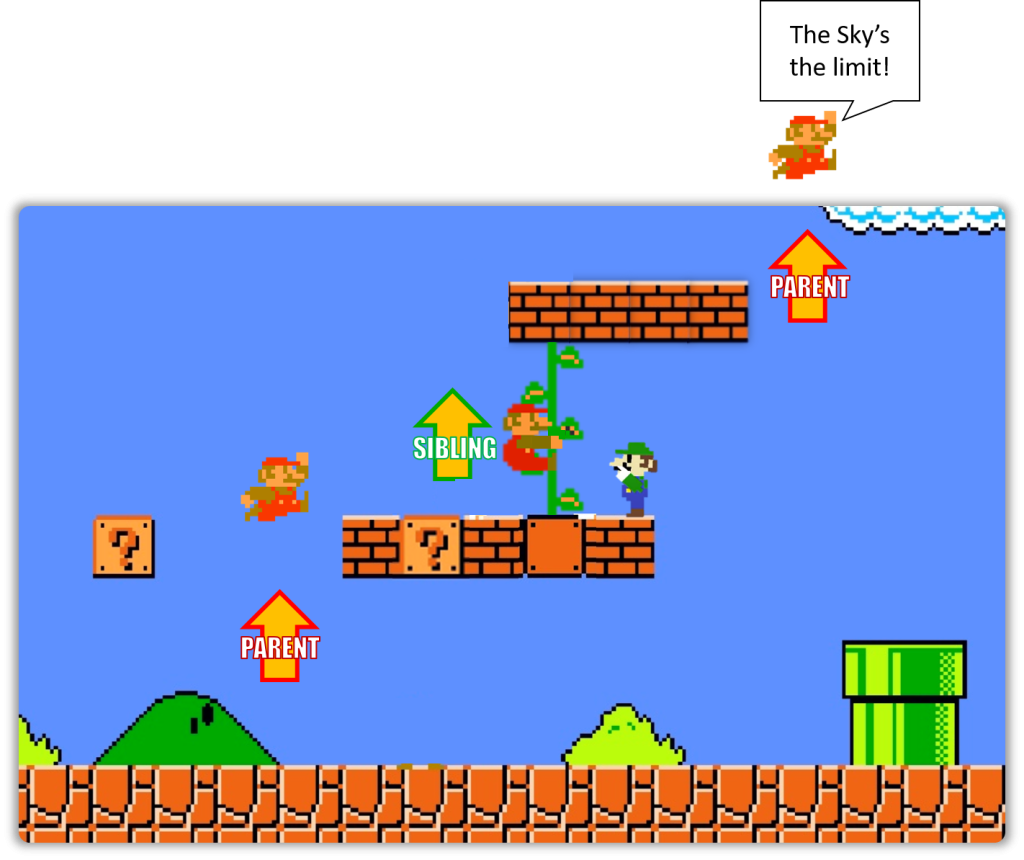
Your Beloved Siblings
As you can see, we have already located the HTML responsible for the description, but that is not what you are interested in.
You might want to extract the name, so how will we travel to that section?
Sure, you could simply right-click and inspect that particular element, or manually click through the nodes in the DOM until you reach the element of interest, but there are instances where this is not possible.
It’s in those instances where you have to rely on siblings.

As always, lets first craft an Xpath for the item we have detected.
//div[@class='product-card__content-footer']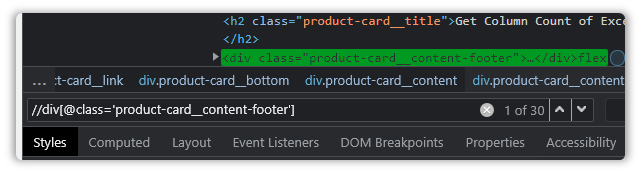
Oh, but what is this?
There are thirty instances of our Xpath.
Is it time for the parents to intervene?
No, not yet.
We have to refine a bit more before we rely on parents.
(//div[@class='product-card__content-footer'])[24]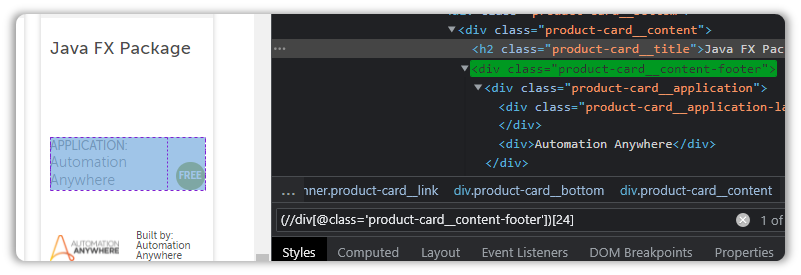
There is another way to define this, which we will explore in the next section.
Now that we have our Xpath, it’s time we made a little road trip to the Title with siblings!
Simply append a forward slash and add the text “preceding-sibling” like so:
(//div[@class='product-card__content-footer'])[24]/preceding-sibling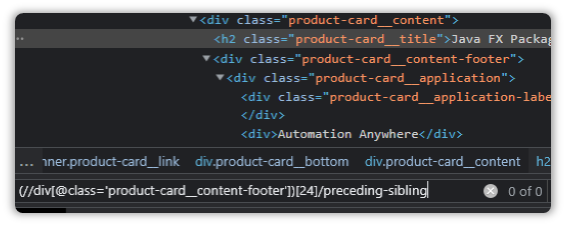
And it detects nothing!
That is because we haven’t asked it which sibling it ought to detect.
A node can have a variable number of subnodes, which is why we have to specify which one we are interested in.
Add a “::h2” and that will tell the Xpath that we are interested in the h2 sibling that is just behind us.
(//div[@class='product-card__content-footer'])[24]/preceding-sibling::h2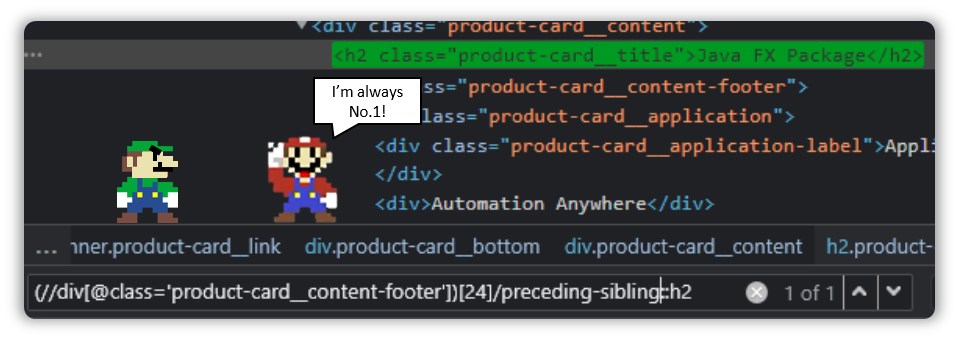
If you have a sibling present ahead of you, then it becomes following-sibling.
(//h2[@class='product-card__title' and text()='Java FX Package'])/following-sibling::div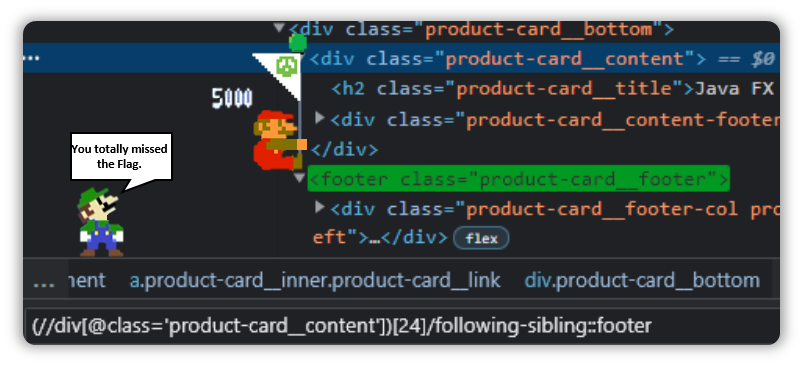
Onto the next section.
How to Use Parents. Wait, That Didn’t Come Out Right…
If you observe the DOM closely, you will notice that the link to the Java FX Package is visible right above the Header tag.
Let’s use the same Xpath as a stepping stone and make our way up from there.
(//h2[@class='product-card__title'])[24]And just like earlier, let’s append a forward slash followed by the keyword “parent” and then a “::a” since that is what we are interested in.
(//h2[@class='product-card__title'])[24]/parent::a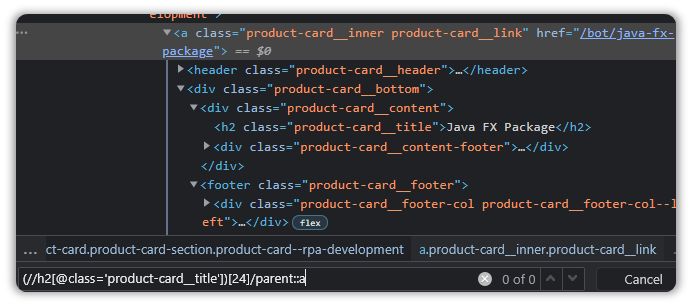
Hmm.
That didn’t work.
How about adding a “div”?
(//h2[@class='product-card__title'])[24]/parent::div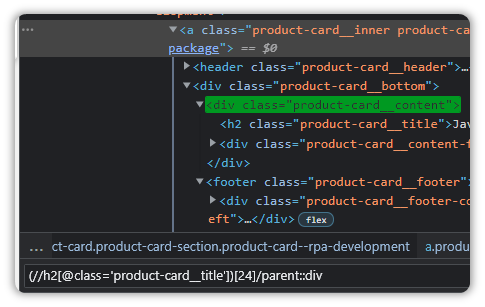
Ok, so that means we have to travel node by node, as opposed to directly accessing the element…well it makes sense since the initial Xpath only has a single parent.
(//h2[@class='product-card__title'])[24]/parent::div/parent::div/preceding-sibling::header/parent::a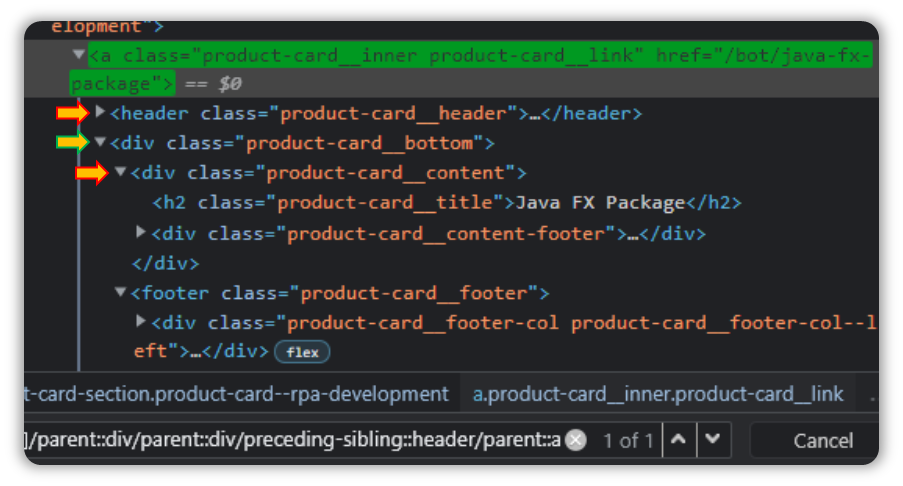
That worked, but it still needs few more tags.
This works out well for us but tell me,
When do you become a parent?
When You Have a Child!
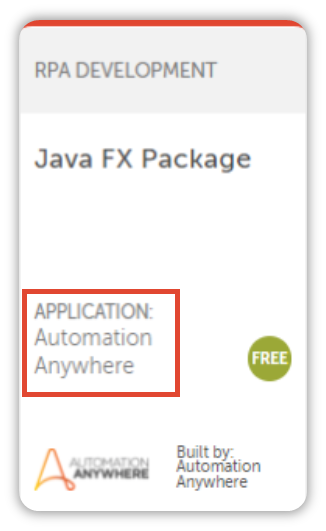
Lets look at a different section.
I want to retrieve the Description this time, so lets see how thats done.
(//div[@class='product-cards_product-card__content-footer__tKgZR'])[27]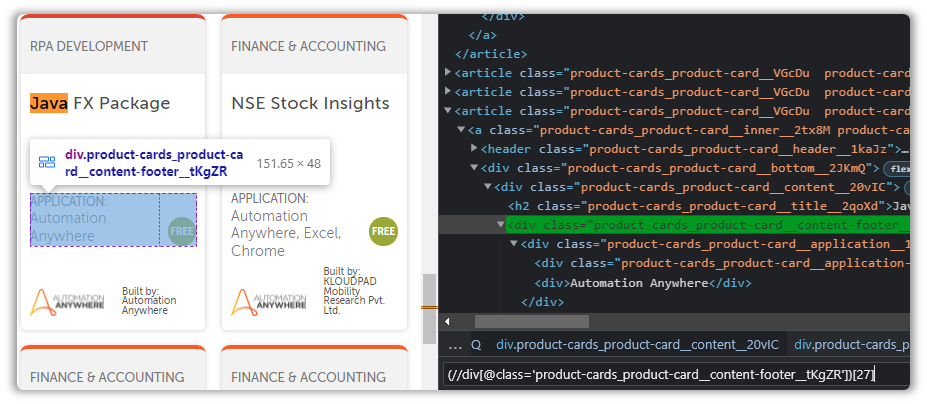
We can’t directly access the text from this node, and we have to travel inside. That is performed using child.
By now I’m pretty sure you’ve recognized the pattern we have to follow here.
Observing the DOM and append /child tags and maybe a few other suitable tags.
(//div[@class='product-cards_product-card__content-footer__tKgZR'])[27]/child::div/child::div/following-sibling::div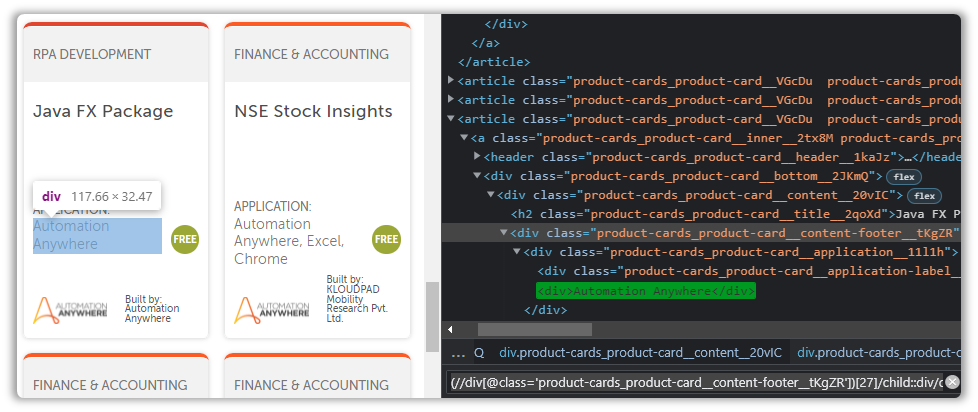
Child is quite useful, but you should never forget your ancestral roots.
Pay Respect to Your Ancestors
Ancestors are quite powerful as well.
Instead of spending time on the road, you can instead book a ticket and get there in a flash.
Let’s visit our hyperlink use case and see if the Ancestor can help us there, but before that, lets see how many links it will take for us to get to the node containing the Hyperlink, starting from the Xpath we currently have.
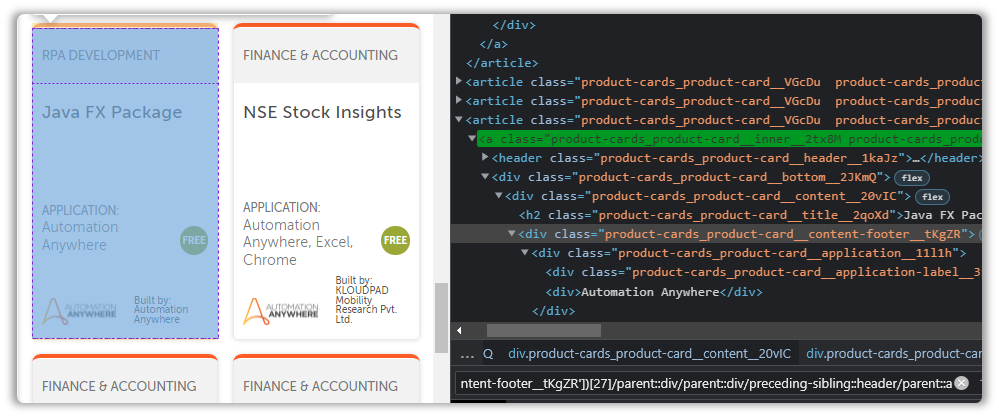
(//div[@class='product-cards_product-card__content-footer__tKgZR'])[27]/parent::div/parent::div/preceding-sibling::header/parent::aA lot apparently…
Wait what are you doing?

What about Ancestor?
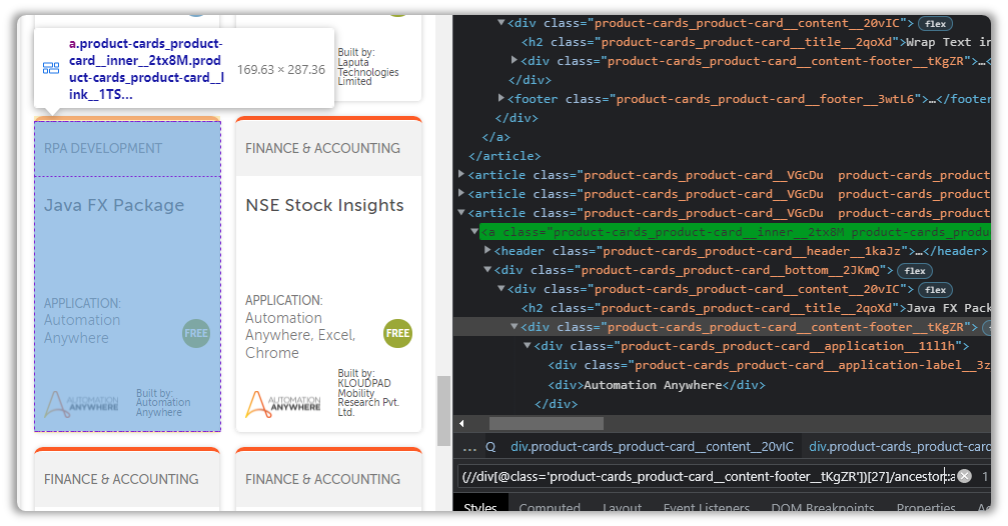
(//div[@class='product-cards_product-card__content-footer__tKgZR'])[27]/ancestor::aAre you starting to see how useful all of this can be?
Not Helps with Negation
The not function is what we are going to conclude with.
The not function is not used as often because basic to intermediate Xpaths solve 90% of your issues. It’s only in those rare instances where you have to rely on not.
But it is useful to know, for when you luck out and face those unicorn situations where you just have to negate Xpaths, or just segments of it.
Lets look at one such example, no shall we?
Say you are trying to upload a video to your YouTube account.
You have followed everything you have learned at TheCodingTheory like the good student you are(don’t forget to drop a like), but this particular Xpath is being a little annoying.
//div[@id='textbox']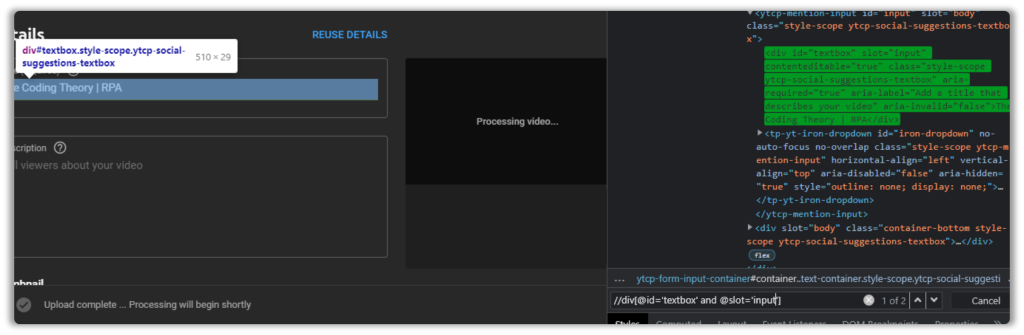
You can add multiple attributes as well by using the keywords and, or like so:
//div[@id='textbox' and @slot='input']But even then, it detects two items.
Let’s observe it some more.
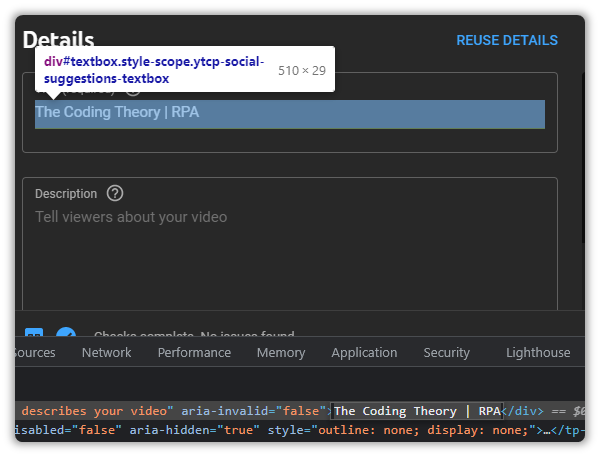
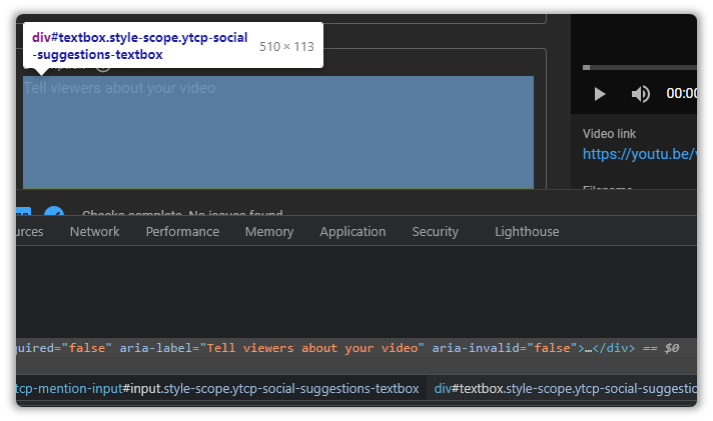
If you look closely, you will notice that the first Text Field contains text, while the other doesn’t.
We can use this to our advantage like so:
//div[@id='textbox' and contains(text(),' ')]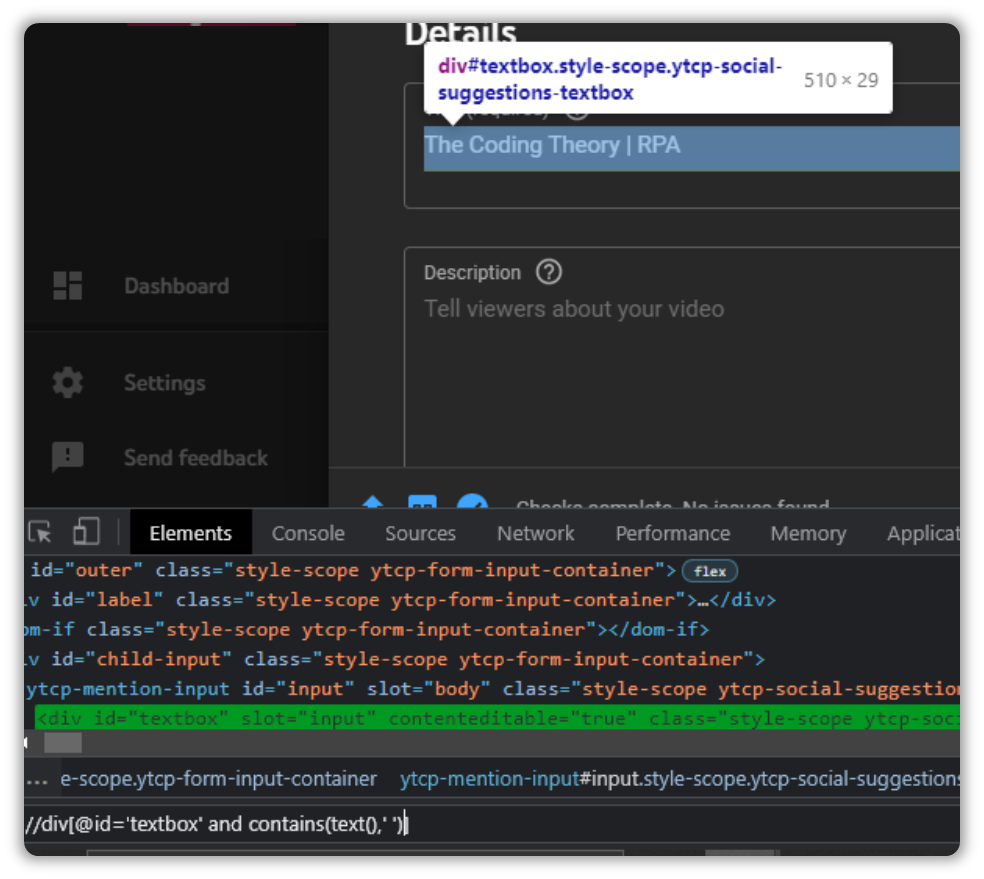
I think you can see where I am going with this, and probably predicted what my next move is going to be.
//div[@id='textbox' and not(contains(text(),' '))]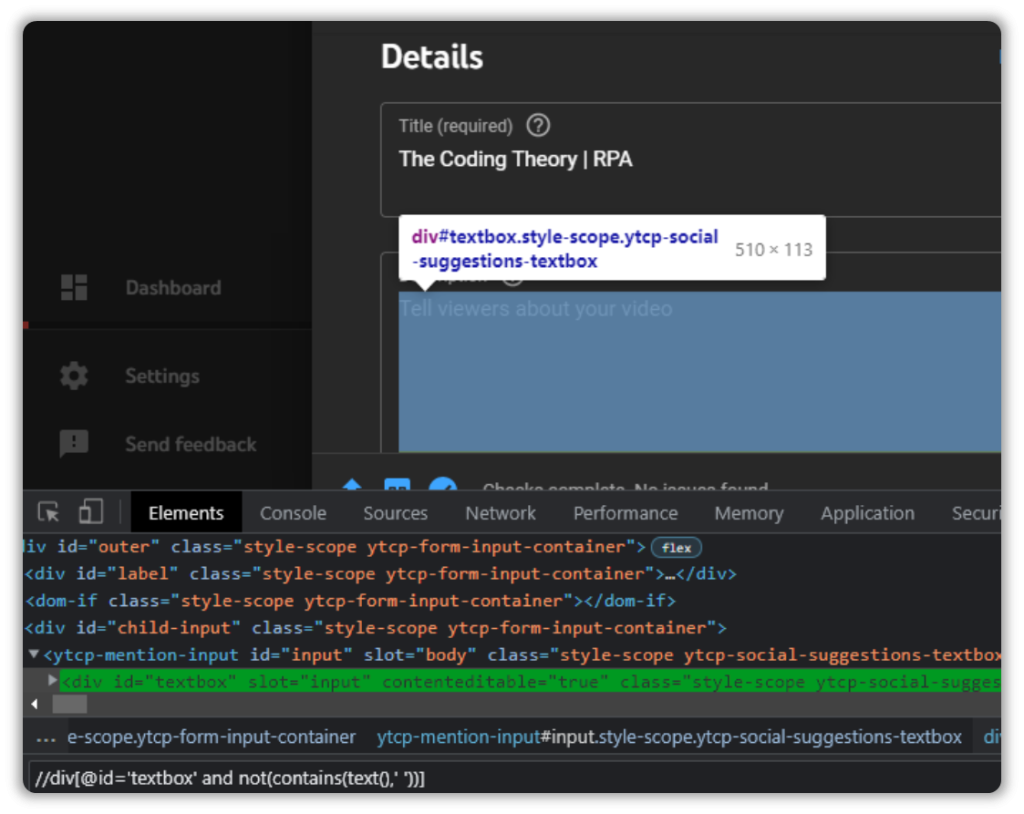
And thats how you negate selections to capture the elements you want.
In Conclusion
Once you learn Xpaths, web automation becomes really simple.
You won’t remember everything, heck even I find myself going back to dear ol’ Google from time to time because even I forget things like most people.
That being said, Xpaths aren’t difficult to pick up on.
Like with any other concept, you have to spend some time with it to get a hang of it.
Hello Ashwin,
Thank you so much for your valuable, detailed explanations.
I appreciate
Hi Semih,
Appreciate the feedback!
If there are any topics you’d like me to explore then feel free to offer suggestions.
Kind Regards,
TCT