
AA: Stop Recording and Start Capturing!

Those new to RPA, will be new to Web Automation.

Some of you might have worked with Selenium, and if so then Web Automation with Automation Anywhere won’t be difficult to pick up on.
Web Automation isn’t easy, but it isn’t difficult either.
It resides in the Goldilocks zone for the most part, but that doesn’t stop her from occasionally nabbing some of daddy bear’s porridge whenever she gets the chance to.

We Have a Universal Recorder Don’t We?
Yes we do, BUT Goldilocks likes to change her mind often.
Today she will eat out of baby bear’s bowl, and tomorrow she will order takeouts and sleep on Mama Bear’s bed.
Your Analogies are Getting Out of Whack.
When automating websites, you don’t necessarily follow the exact same route, and interact with the exact same elements in the exact same manner, nor do these elements remain constant throughout.
English Please.
This is why I invoked the Goldilocks Method, to make it sound less technical.

Could You Use Another Example?
Let’s use this analogy instead, you want to purchase a bowl for Goldilocks in the hopes that it will stop her from breaking into random people’s houses.
You head over to amazon, start browsing through the catalog and then it hits you.
“I’m an RPA Developer aren’t I? Why waste time with this manual stuff, I’ll develop a bot to do this instead!”
You head back to your Control Room, click Automations, Click Create new Bot, enter a name and then hit Universal Recorder.

The bot then records all your interactions and when you try to run it, it runs…
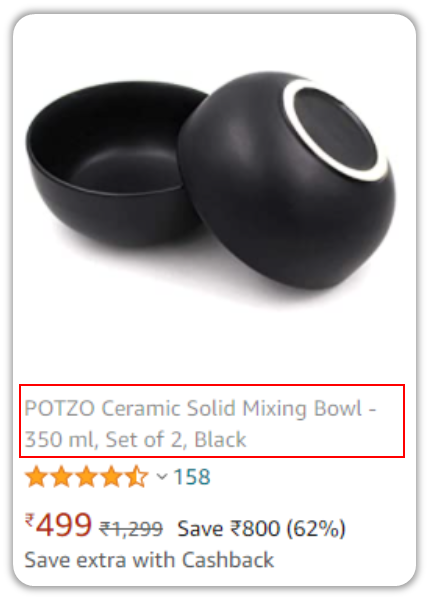

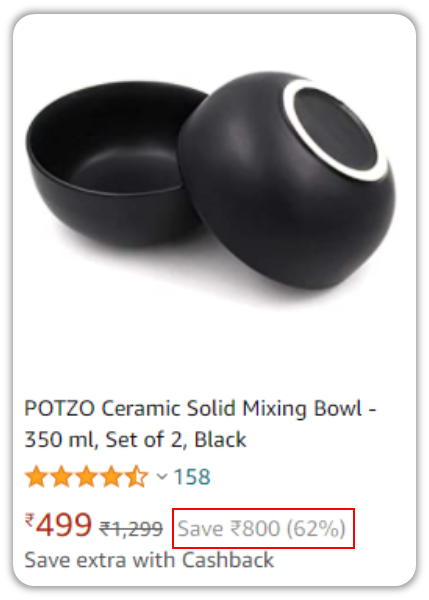
But it just keeps clicking on the same object again and again.
Turns out, our bot wasn’t smart enough to realize that you wanted to capture the name, price, discount percentage etc.
This isn’t exactly a limitation of Universal Recorder; it wasn’t designed to predict your intentions, or offer options based on your selection. It’s just a recorder.
Generally, we only use the Universal Recorder when the application being automated is very rigid in its navigation, or if it is hosted on a server that can only be accessed through Citrix.
You can, however, use the Universal recorder to Capture the objects you want to interact with, then refine the Object Properties later.
It all boils down to a matter of preference.
For anything additional, we have to provide our inputs to the mini-recorder which we are going to visit next.
Meet My Son.
Universal Recorder has a miniature version of itself which goes by the name of Recorder: Capture Action.

Not only is he capable of capturing desktop and web based objects, he also allows us to intelligently interact with objects.
I said “intelligently”, because the options offered by the Recorder: Capture Action aren’t static; it actually does its homework and offers options based on the captured object’s properties.
Let’s look at a couple of examples.
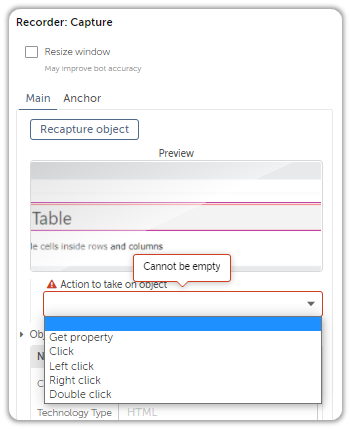
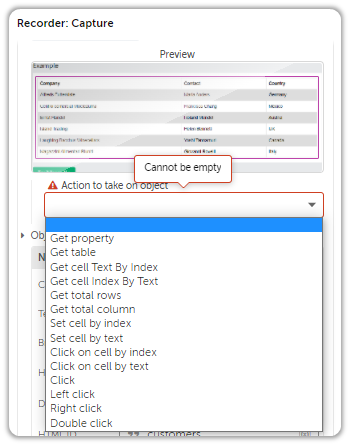
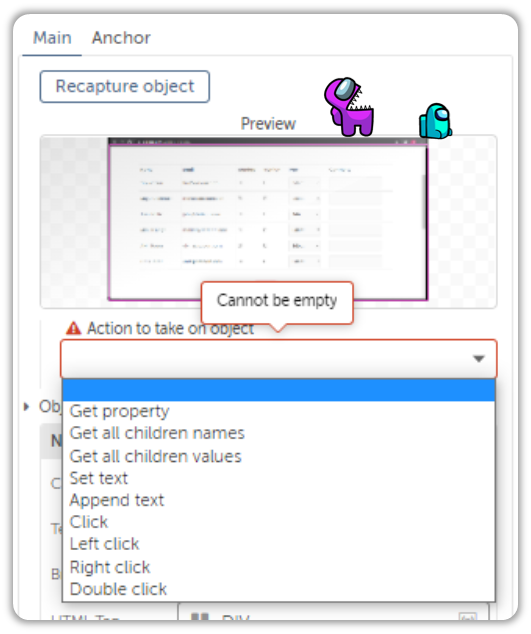
As you can see, the options vary depending upon the object being captured.
Isn’t that neat?
You don’t think that’s neat?
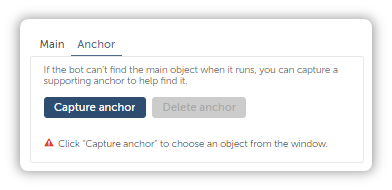
Then how about this, the Recorder Action also comes with an Anchor that you can capture to solidify your selection.
Simply toggle over to Anchor, and click Capture Anchor.
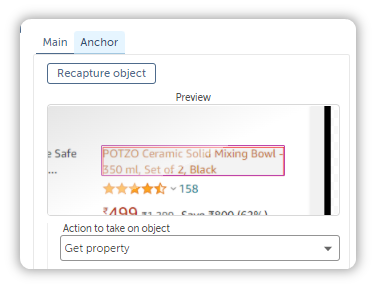
The bot will automatically capture the Object and ask you whether this is the item you wanted to capture, before asking you to specify the anchor.
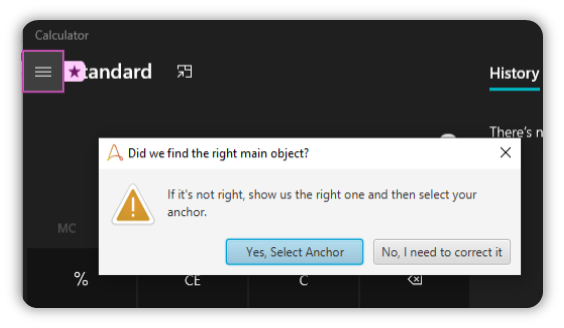

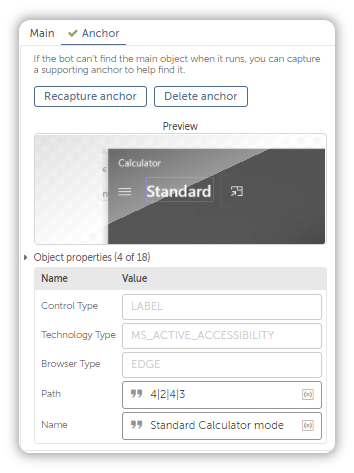
The Anchor can’t be used for Web Browsers just yet. I’m not sure why that is, but I’m pretty sure that issue will be fixed in the next update.
Let’s head back to our data scraping.
Scraping Text, Hyperlinks…and Images?
I had penned a series on data scrapping where I have explored Xpaths in-depth, so I will only be exploring those aspects of the Recorder Action which aren’t all that well known.
Remember this, for each item you wish to extract, you have to craft an Xpath which uniquely identifies it.
Without this, your web automation won’t work, so bear this in mind before you proceed. I would suggest proceeding once you are comfortable creating Xpaths.
First, pay attention to the Object Properties present in the screenshot below:
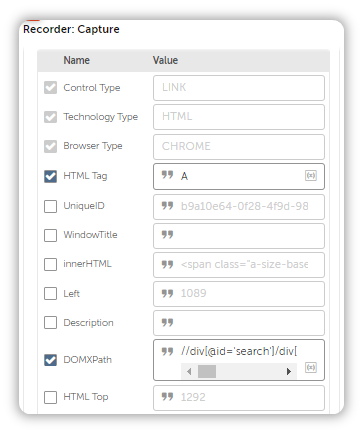
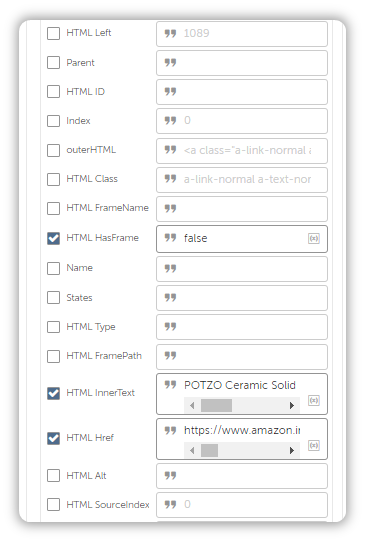
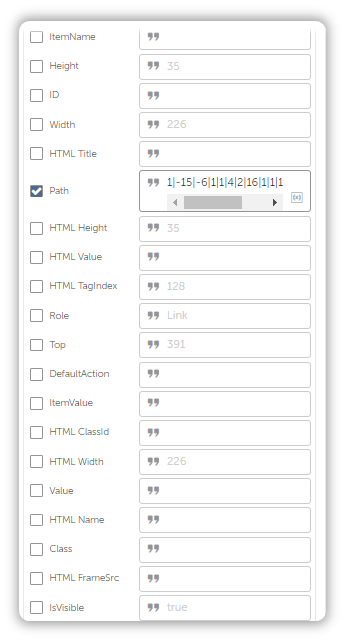
Understand this, you can use any or all Object Properties to anchor onto a web element that you wish the bot should interact with.
You can also retrieve whichever you want Object Property once you toggle it to Get Property.
Just make sure you have entered the text as shown in the Object Properties like so:
(//span[@class='a-size-base a-color-base a-text-normal'])[5]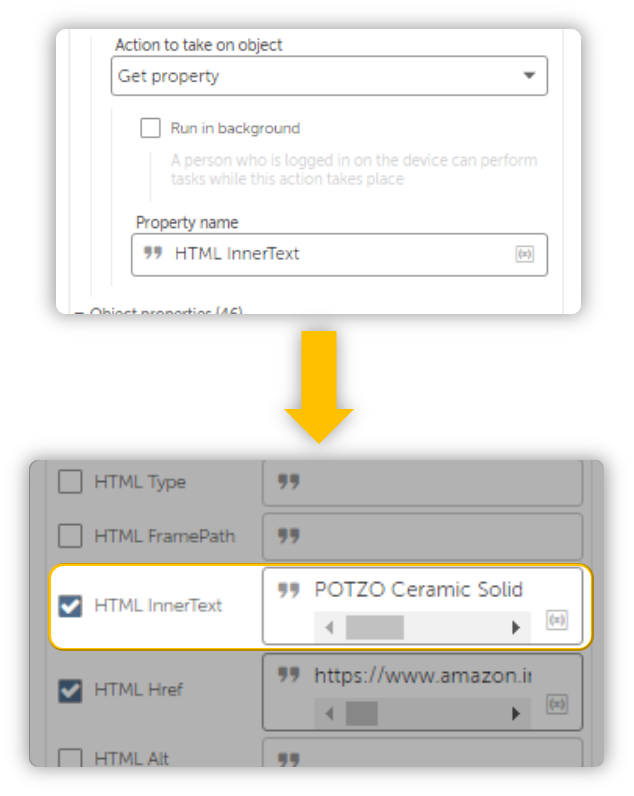
This way, we can retrieve the Product Name, Cost, URL…but what about its Image? How will we retrieve that?
No one goes shopping without actually looking at the product they are going to purchase. Even the rich always look at what they are putting their money into before making a purchase, which is why they are rich.

-Jim Rohn
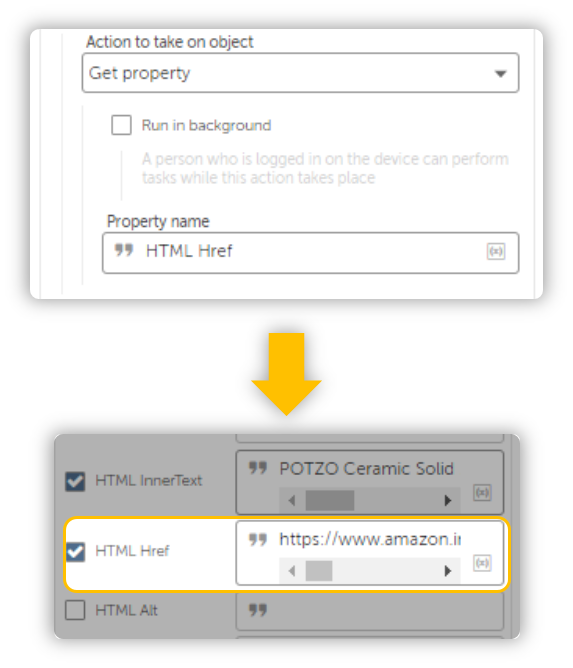
Just like above, using another property called HTML Href will allow you to fetch the Image URL.
Make sure you craft an Xpath which will uniquely identify the image you are interested in retrieving.
(//div[@class='a-section aok-relative s-image-square-aspect'])[5]
but the bot won’t know what to do with the URL it just retrieved. We have to tell it to download whatever that hyperlink is pointing towards.
There is an Action present in the Browser Action Package which will help you with that. This could also be a certification exam question…or maybe it isn’t.

Can you guess what it is?
Go through the Browser Action Package and see if you can figure it out.
.
.
.
.
.
Browser: Download File Action
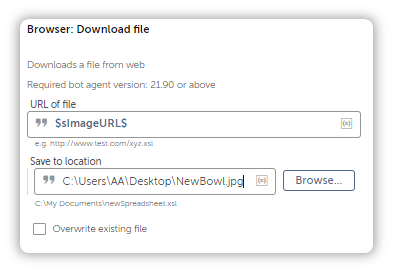
With this, we are in a better position to make decisions and purchase a bowl that will suit Goldilocks taste, in so far as the bowl is concerned.
Don’t expect RPA to cook the porridge as well.
Will this Work for CAPTCHA?
Let’s see what Google-san has to say about that.
There are legal issue with automating CAPTCHAs.
Don’t believe me?
Why would they put a CAPTCHA there in the first place? Its done to prevent spam, which is usually performed by bots developed by trolls. Its these darn trolls that are giving bots a bad name.
Simply put, if a bot can’t spam, it can’t automate either.
You are better off leaving it alone, and even if you manage to retrieve the CAPTCHA URL, the Browser: Download Action will have a hard time downloading it.
CAPTCHAs are mostly base64 encrypted. Yes, I butchered that last bit because I don’t know what its actual name is or what the heck it even means, but the point remains, that you can’t use the steps above to retrieve the CAPTCHA text.
What about OCR?
OCR works, but not always.
The slashes you see in CAPTCHAs prevent our OCR from extracting the right text.

You can’t develop a solution that kinda works and expect it to work without kinda failing every now and then.
Either you can request the client to purchase an attended license instead, and propose a solution that meets their demands, or you could develop a bot to continue processing until it detects a CAPTCHA, and then draft a mail to notify the end user that it requires his/her assistance to proceed.
I bet there are better ways to handle situations like this, and what I have detailed above are the workarounds I had suggested and implemented in my projects.
In Conclusion
I hope this has given you an idea of how the Capture Action works, and how you can utilize its capabilities to the fullest.
I bet there are more ways in which the Capture Action can be utilized, I generally stick with the DOMXpath since that is what I am comfortable with.
Maybe you can discover something unique and share it with the rest of us.