
Extracting Tables That Aren’t Tables: A Smarter Approach
If you’ve been following my previous posts, you would have realized that although the process delivers results, it delivers them after a considerable amount of time.
Not only is the execution time lengthy, there is a level of complexity which is unavoidable, since we have to study the HTML structure first, then test out various Xpath patterns until we craft one reliable enough to scrap the data we are interested in.
Then there is the workflow we have to develop which will scrap data and output it into a Table as it is. The Xpath would have to be further refined as well, so that we can loop through the tags in a sequential order.
Imagine for a moment, that we had to scrap data off a web table spanning thousands of rows.
Think of how long you’d have to wait, as you sat there waiting for the execution to end, hoping your life doesn’t come to an end first.

What you are about to learn will supercharge your table extraction.
With this, your bot will reach the finish line before you reach pearly gates of heaven.
What is Special About This Technique?
We will be storing the data into a CSV file.
CSV files consist of data where the rows items are separated by commas, and the columns by newline feed.
To achieve this transformation, we will use regex to convert the data into comma separated values that we can write to a CSV file.
Regex Again? C’mon.
It’s not my fault that Regex is so darn useful.
It amazing what you can do with these funky patterns, once you learn how to use them.
Something That is Not So Amazing
Automation Anywhere has decided to exclude the Regex Action Package from Community Edition, and that upsets me.
NOTE: Packages can now directly be imported into Community Edition.
I wrote this article a while back and forgot to publish it, as my manager finally caught a hold of me and drafted me into the project-ridden warzone.
My constant whining on the Apeople Forum did the job!
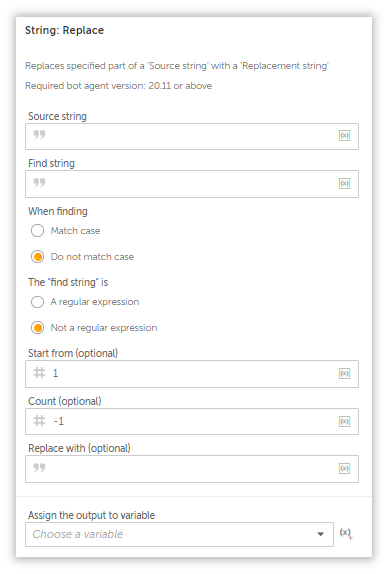
However, they do have an action in the String Package called String: Replace which supports regex. It has its limitations, but we have to become creative with whatever is available to get the job done.
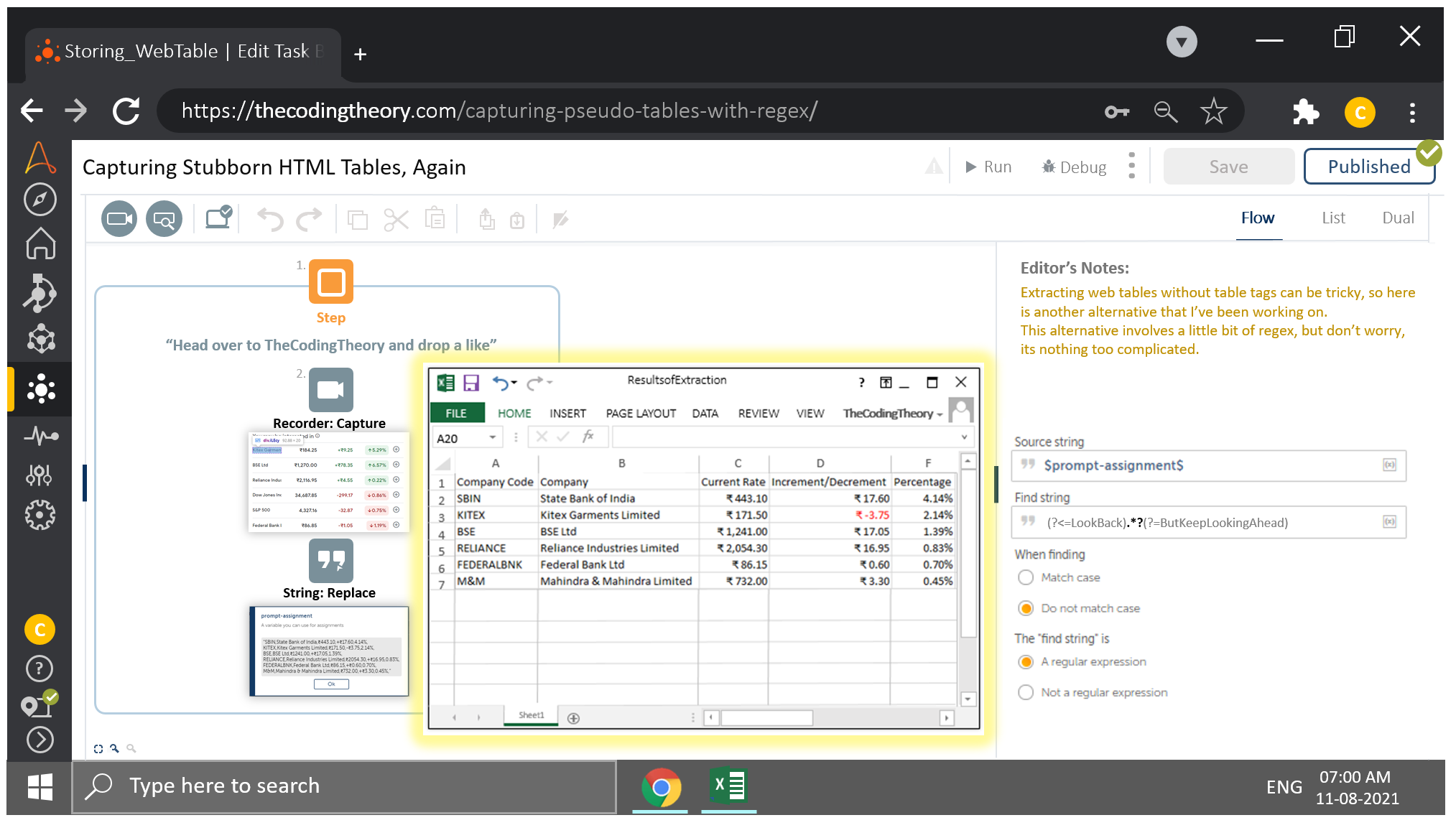
First Thing’s First
Open up the browser and navigate to Google Finance.
All of this can be achieved in a single step, and if you are coming from a coding background, you know this is amazing.
After that is done, we will inspect our web table and craft the Xpath responsible for highlighting the entire table and drag in a Recorder: Capture Action to retrieve the data.
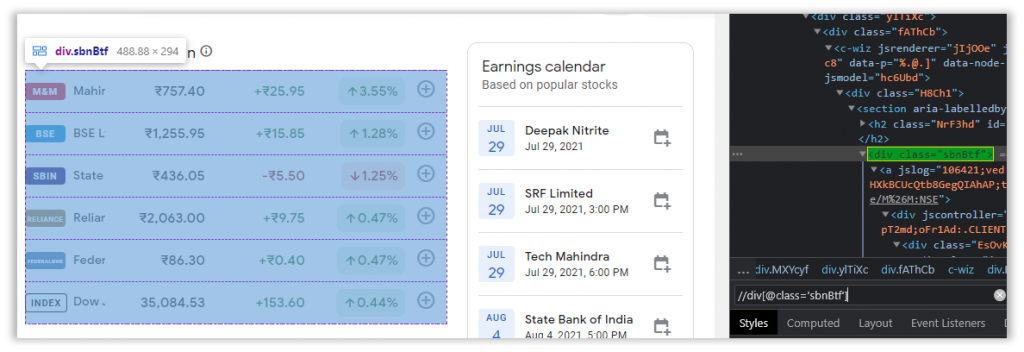
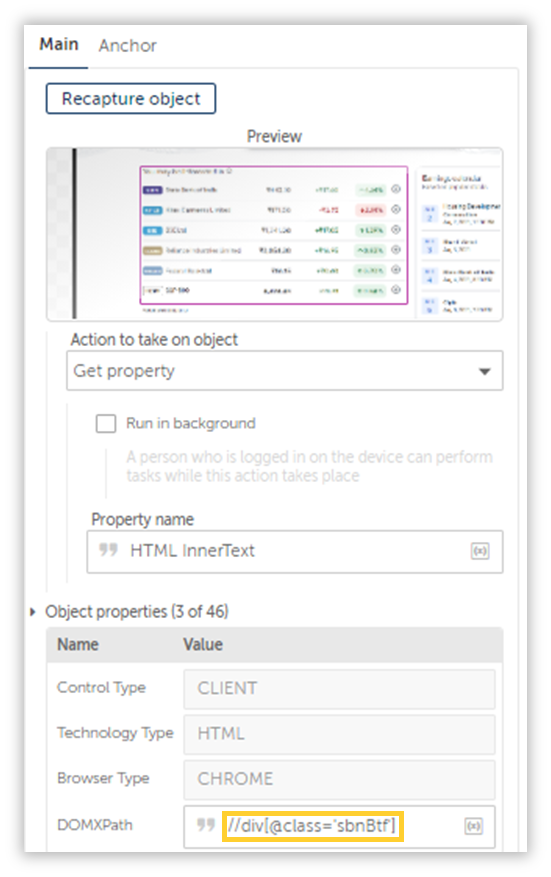
Lets try running this in debug and see what turns up.
Nice!
Our bot was able to extract the data in its entirety, however the data contains special characters which is why it’s all jumbled up.
But that is alright.
We have regex don’t we?
Yes We Do
Onto the second step in our process.
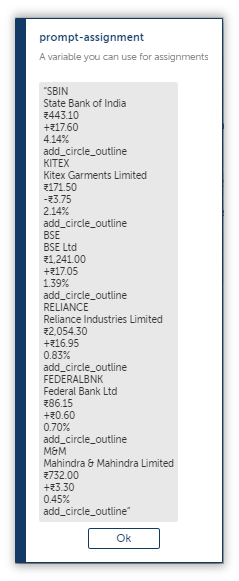
First, lets take a look at the extracted string.
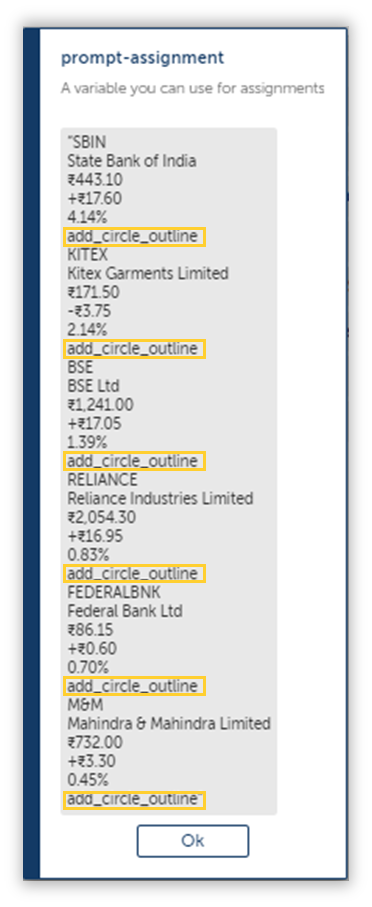
Each column is separated by “add_circle_outline”.
I don’t know where that came from, and I want to get rid of it ASAP.
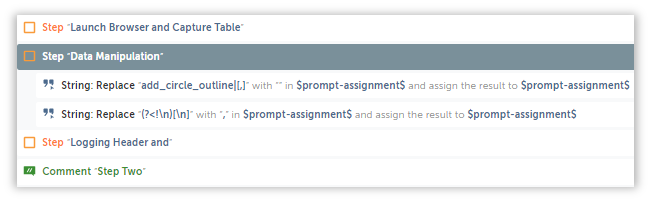
If we were to replace this with a suitable character, then we can separate them without any hassle, but unfortunately for us, the String: Replace can’t replace a pattern with another regex pattern, so we will replace it with a null string instead.
add_circle_outline|[,] //Few lines items contain commas(numbers) and has to be removed since it is a delimiter.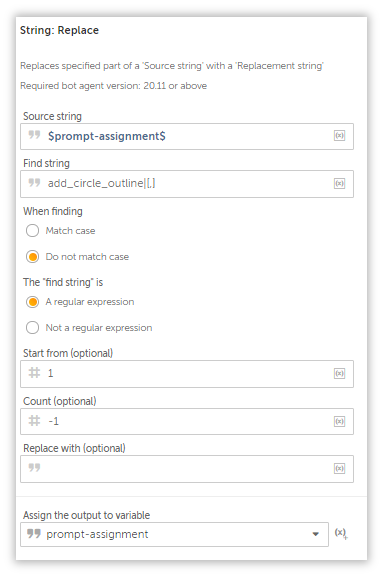
You can either leave it blank, or create a null string variable($sNull$) and assign it to the action.
Yes, yes, there are String System variables such as $String:Newline$ and $String:CarriageFeed$, but none of them are ideal for this particular use case.
Let’s try running it until here and see what turns up.
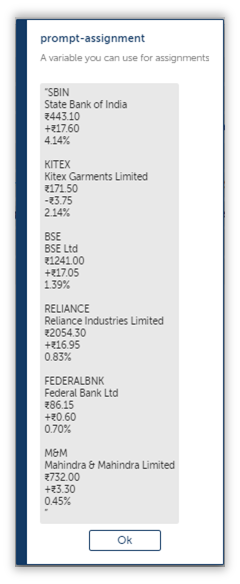
As you can see, the text has been removed, and now we can move onto the next regex pattern which will convert our data into a csv friendly format.
This Is What Adds the Commas
To perform the last operation, we have to develop a pattern to detect newlines that exclude the newlines from the string we just removed in the previous step.
Here is a screenshot of what it is we are trying to achieve.
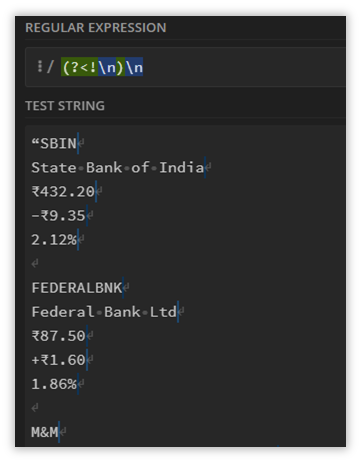
The newlines are matched for each line item except for the gaps left behind after we removed the “add_circle_outline”.
(?<!\n)\nI will explain the pattern given above.
The type of assertion we are using here is called a Negative LookBack. The Positive LookBack as shown below, detects elements shown in the screenshot below.
(?<=\n)\n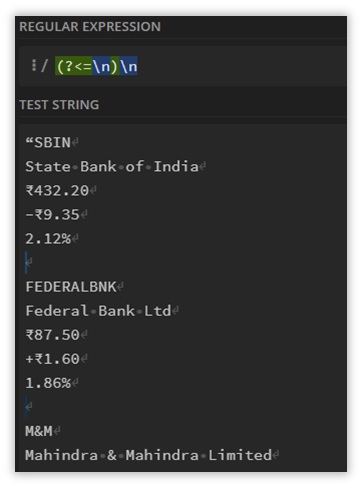
The reason I used a negative assertion, is so that I can match the newlines other than the one left behind after replacing the “add_circle_outline” text.
Once we plug this into another String: Replace Action, this is the result we will arrive at:
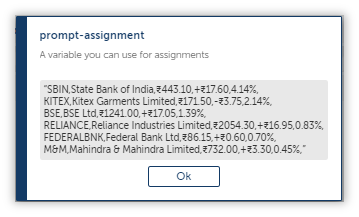
Almost Reached The Finished Line!
Onto the last and final step, where we will write our refined Data Table to a csv file.
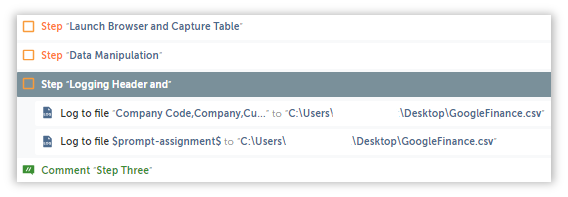
Remember, the table we are extracting doesn’t come with any headers, so lets add them by logging them into either an existing csv file, or a new one(I prefer using a new one).
Company Code,Company,Current Rate,Increment/Decrement,Percentage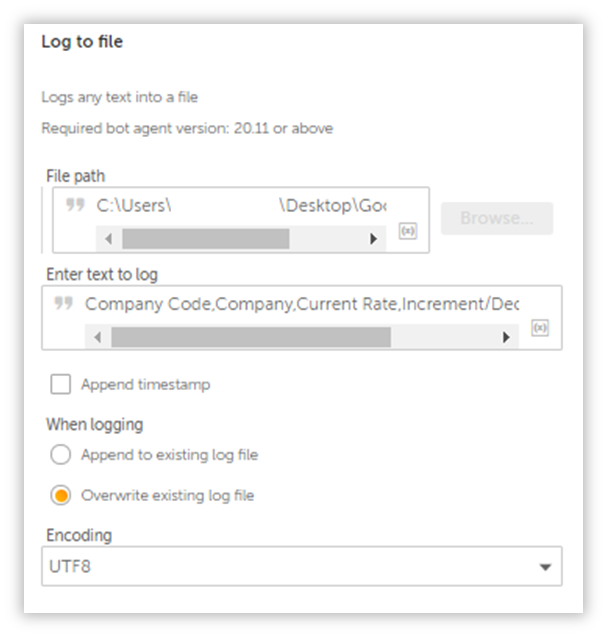
Make sure you append a .csv to the end of the file, as this Action can log data into text files as well.
Now for the data that will make up our Table:
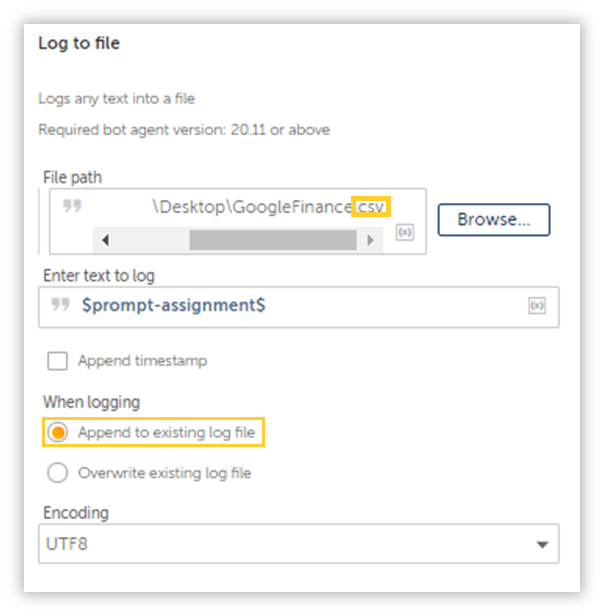
Make sure you toggle the option to “Append to existing log file”, because the second batch of data has to end up in the exact same csv file. Also, you might have to play around with the Encoding in case the data doesn’t populate with the right characters.
If everything work out well, then you will end up with a proper table neatly tucked into a csv file:
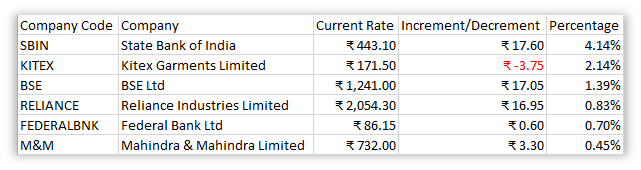
Try this exercise and see if you are able to achieve the same result.
This to me, was enjoyable – and I hope it will be for you as well.
Awesome Content!!!!
Hi Bhargavi,
Appreciate the feedback, if there are any topics you’d like me to explore then don’t hesitate to reach out to me either here or over at the APeople forum.
Kind Regards,
TCT
Thanks for your blog, nice to read. Do not stop.